DetailTTS: Learning Residual Detail Information
for Zero-shot Text-to-speech
for Zero-shot Text-to-speech
Fengping Wang1, Bingsong Bai1, Qifei Li1, Jinlong Xue1, Yayue Deng1, Zhengqi Wen2, Ya Li1,*
1. Abstract
Traditional text-to-speech (TTS) systems often face challenges in aligning text and speech, leading to the omission of critical linguistic and acoustic details. This misalignment creates an information gap, which existing methods attempt to address by incorporating additional inputs, but these often introduce data inconsistencies and increase complexity. To address these issues, we propose DetailTTS, a zero-shot TTS system based on a conditional variational autoencoder. It incorporates two key components: the Prior Detail Module and the Duration Detail Module, which capture residual detail information missed during alignment. These modules effectively enhance the model’s ability to retain fine-grained details, significantly improving speech quality while simplifying the model by obviating the need for additional inputs. Experiments on the WenetSpeech4TTS dataset show that DetailTTS outperforms traditional TTS systems in both naturalness and speaker similarity, even in zero-shot scenarios.
2. Model Architecture
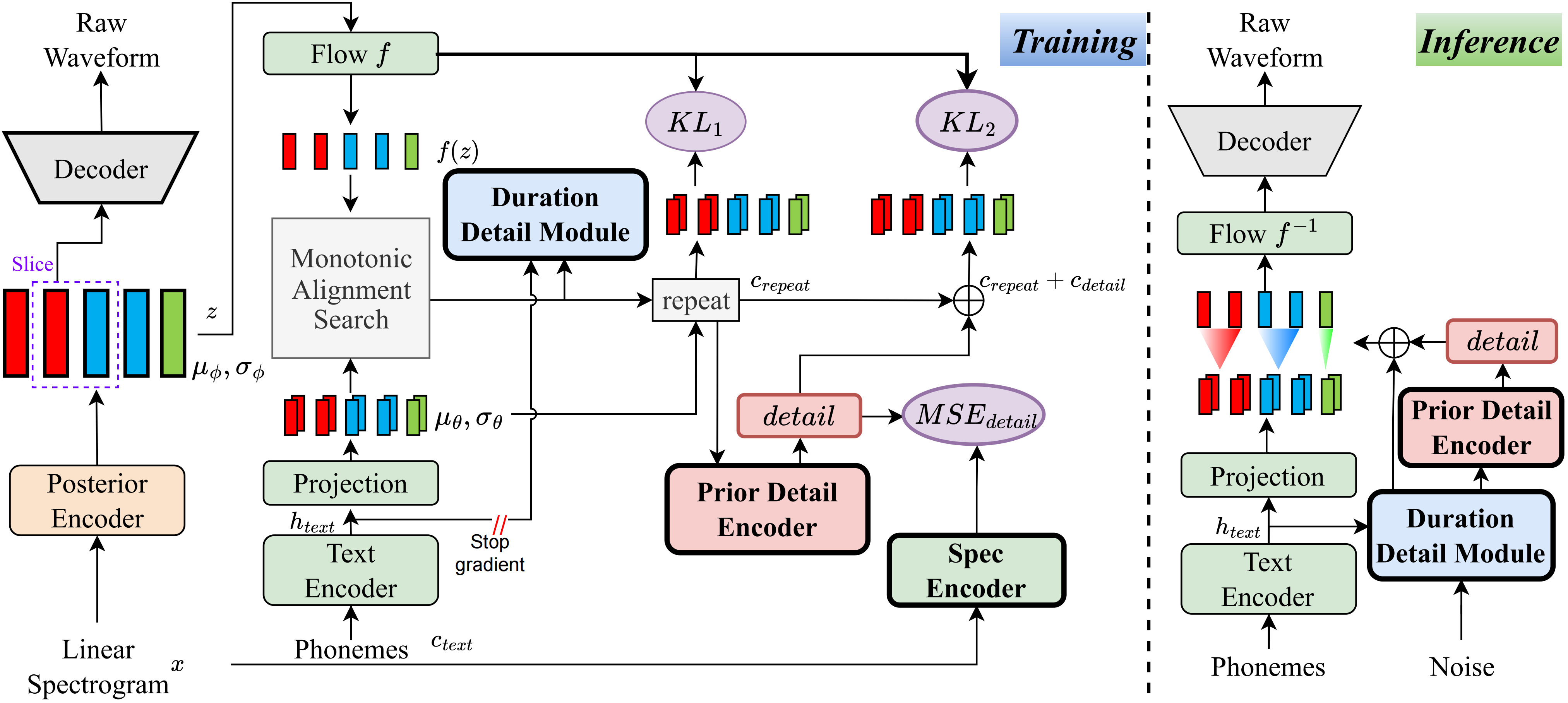
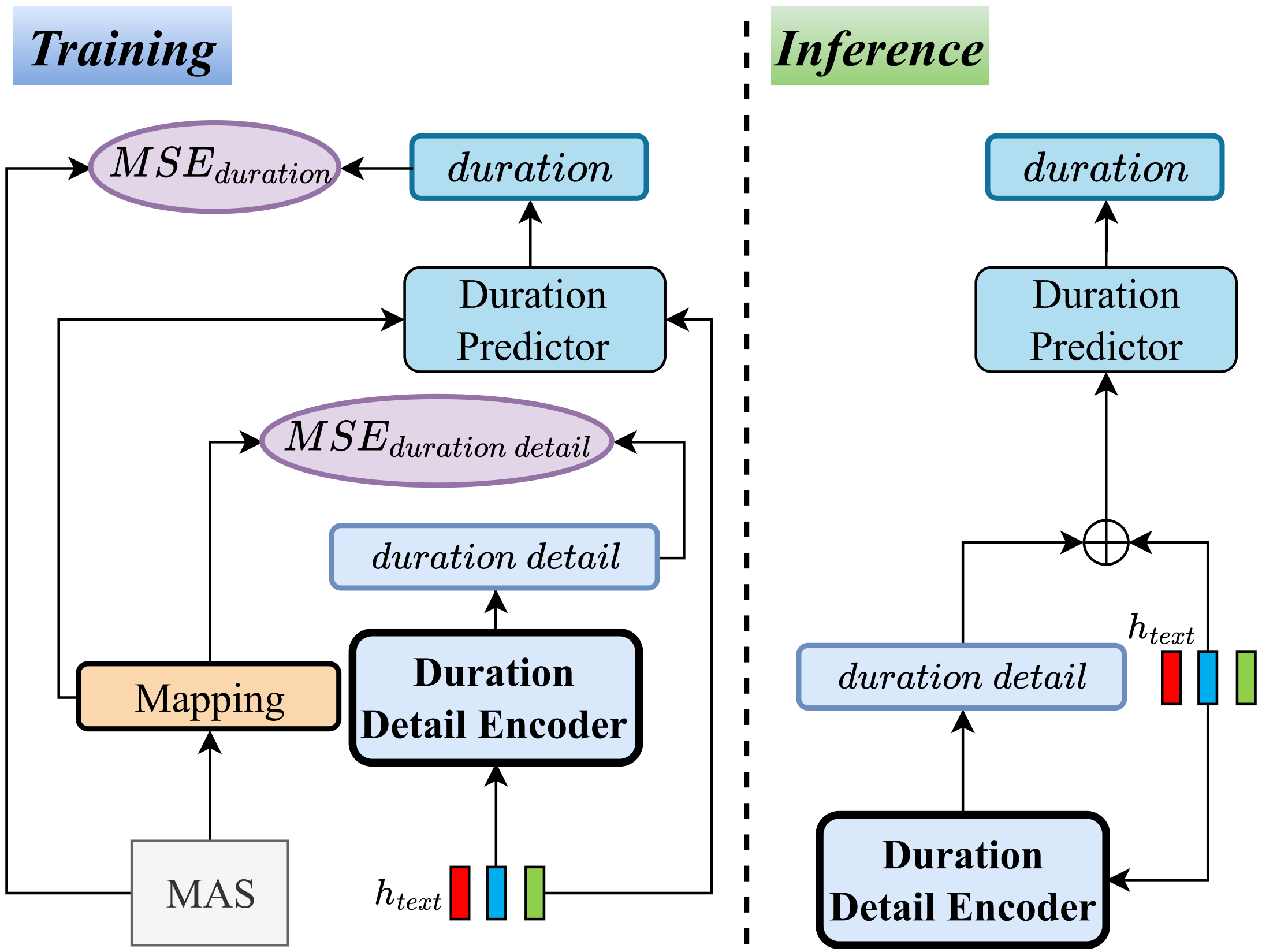
3. Zero-Shot TTS Samples
Seen Speakers
Unseen Speakers
4. t-SNE

We randomly selecte 15 speakers from the test dataset and conducted t-SNE visualization of the speaker embeddings for their synthesized and real speech. The speaker embeddings of synthesized speech and ground truth from the same speaker are closely clustered together, further demonstrating the superiority of our method in terms of speaker similarity.